Data Vault 2.0
The Data Vault 2.0 modelling technique has grown to a standard used in the development of a Data Hub. It is one of the foundations for our data integration projects and is therefore one of the keys to the success of these projects.
Data Vault 2.0
Data Vault 2.0 is an innovative data modeling, methodology and architecture for large scale data platforms providing historical data representation from multiple sources designed to be resilient to environmental changes.
The data model is built on three main components:
![]() HUB : natural business key
HUB : natural business key
![]() LINK : natural business relationship
LINK : natural business relationship
![]() SATELLITE : all context, descriptive data and history
SATELLITE : all context, descriptive data and history
Data Vault Architecture
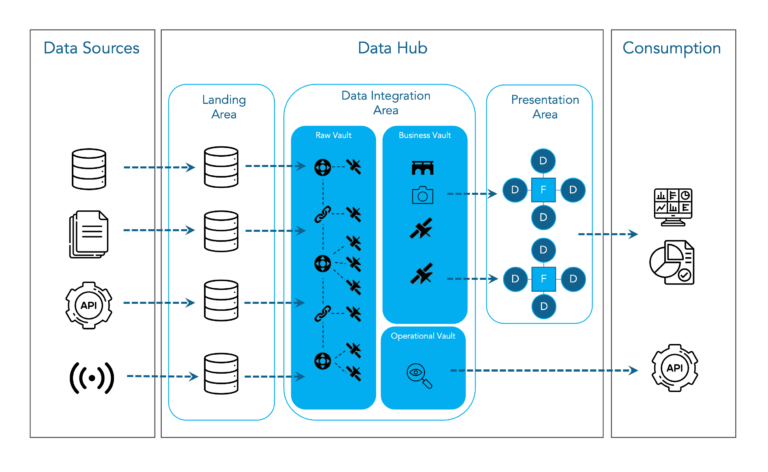
Our general approach for any Data Warehouse projects follows a reference architecture that is based on this Data Vault 2.0 model.
Raw Vault
When building a Raw Vault of all available data sources in an organisation, hard rules are applied to form a big web between the different tables from different source systems. By defining Hubs, Links and Satellites, this web is built, and connections are made without losing any information from the source and so providing all facts. It gives the advantage of always providing all realtime data and history preceding the real time information. The traceability of the data makes the model auditable. Every change is visible in satellite tables with exact time stamps. The model’s resilience to change is notable is the Raw Data Vault when new sources are added, or source systems are deleted or transferred and further on also in de Business Data Vault when a company’s needs or expectations change in time.
Business Vault
The Business Vault is where needs and wishes of the business are applied, and all abundance of information is filtered out. The separation of these two layers makes them resilient to change in the future because all facts are still present in the Raw Vault and by merely changing the soft rules, a whole new truth can be formed without going through the process of extracting new data from the source. Concepts such as PIT and BRIDGE tables are implemented in this layer for performance reasons in the Presentation Area.
Operational Vault
The Operational Vault layer is the interfacing layer for other applications or consumers NOT used for reporting purposes.
These consumers are not interested in the history of data and therefore we typically built views on top of the Raw Vault layer.
Presentation Area
Within the Presentation Area the business processes are modeled in a dimensional model (Kimball). These models are virtualized (views) and are representing the version of the truth. Dimensional models are designed for reports and dashboards. The Operational Vault is also part of the Presentation Area and is a view on top of the RAW Data vault layer with the latest status of the RAW data. This layer is directly accessed by operational systems such as API’s.
Advantages of Data Vault 2.0
The Data Vault 2.0 approach offers many advantages such as:
- The support of building your data platform incrementally by integrating source by source or different parts of a single source
- All data is stored at the lowest level of granularity and record all history of change for all attributes
- Resilience to change such as changes in entities, attributes and relationships between entities
- Traceability of all data and data model changes
- Possible to automate the data modeling and pipeline process
Vaultspeed
Data Vault 2.0 was developed specifically to address agility, flexibility, and scalability issues found in the other mainstream data modeling approaches used in the data warehousing space and allows you to automate the data modeling proces and ELT pipelines.
We are specialized in Data Warehouse Automation and therefore we have a solid partnership with Vaultspeed.